贝壳找房流量分发数据回收与治理演进之路 构建高效、可靠的数据处理服务
在数字化浪潮中,数据已成为驱动企业决策与业务增长的核心资产。对于贝壳找房这样连接海量用户、房源与经纪人的居住服务平台而言,流量分发过程中的数据回收与治理,不仅是技术挑战,更是保障平台公平、效率与用户体验的战略基石。本文将系统梳理贝壳找房在流量分发数据领域的处理服务演进之路,揭示其如何通过持续的数据治理,构建起高效、可靠的数据处理体系。
一、起点:数据回收的挑战与初期实践
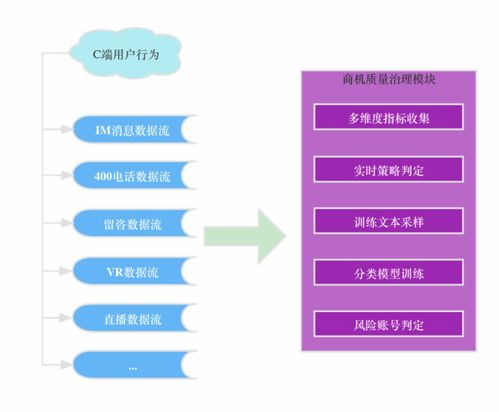
贝壳找房的流量分发场景复杂,涉及搜索、推荐、列表页等多个触点,每天产生TB级的行为日志与业务数据。早期,数据回收面临几大核心挑战:
- 数据源分散:用户点击、浏览、转化等行为数据分布在不同的客户端与服务端,格式不一,采集链路存在丢数、延迟问题。
- 口径不一致:业务方、产品与数据分析团队对“曝光”、“点击”、“有效流量”等关键指标定义存在分歧,导致数据可信度受损。
- 处理效率低下:批处理任务耗时漫长,无法支持实时或准实时的流量效果分析与策略调整。
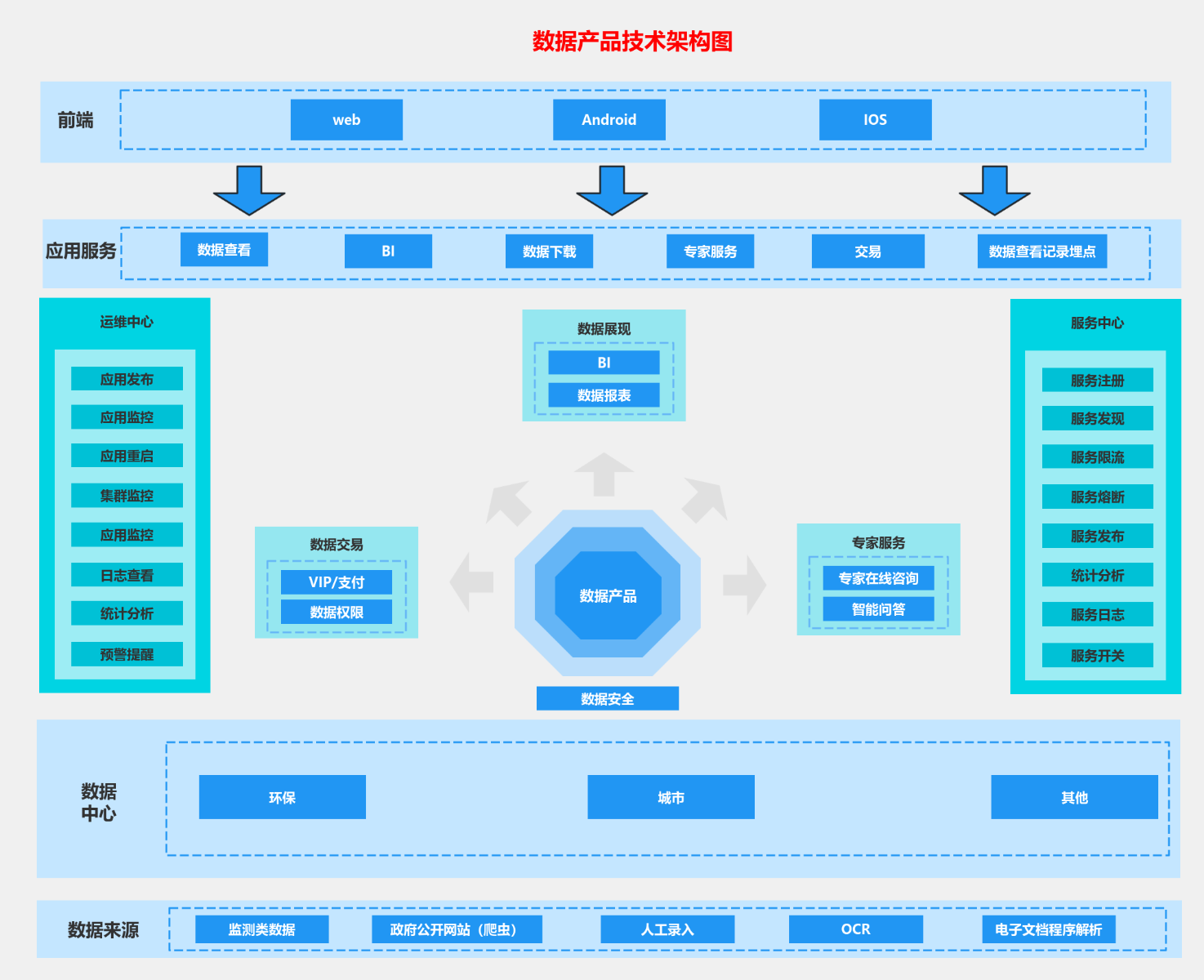
初期,团队通过建立统一的SDK埋点规范、搭建基础的Flink实时计算管道与Hive离线数仓,实现了数据从采集到可查询的初步闭环,为后续治理奠定了基础。
二、演进:体系化治理与平台化服务
随着业务规模扩张与精细化运营需求提升,简单的数据管道已无法满足要求。贝壳启动了数据治理的体系化建设,核心演进方向包括:
- 元数据与数据质量治理:
- 建立全局数据字典,明确定义流量相关指标的业务含义、计算口径与归属部门,实现“一处定义,处处一致”。
- 构建数据质量监控体系,在数据采集、传输、计算的关键节点设置校验规则,对数据延迟、波动、缺失进行实时告警与自动修复,确保下游分析“源头活水清”。
- 实时数仓与流批一体:
- 升级实时计算架构,引入Kafka、Flink、Doris等组件,构建低延迟的实时数仓。这使得流量分发效果(如新策略的CTR、CVR)能在分钟级甚至秒级被感知,助力算法团队快速迭代A/B实验。
- 推动流批一体架构,同一套逻辑代码可同时处理实时流与历史批量数据,减少了维护成本,并保证了实时与离线数据结果的一致性。
- 构建自助式数据产品与服务:
- 将处理后的标准化流量数据,通过数据中台以API、数据集市或BI报表等形式,开放给业务、产品、算法等不同角色。例如,为运营人员提供流量漏斗看板,为算法工程师提供特征数据集,将数据能力产品化、服务化。
三、深化:智能驱动与价值闭环
当前,贝壳的流量分发数据处理服务已进入“智能驱动价值”的深化阶段:
- 智能化治理:利用机器学习模型自动检测数据异常、推断数据血缘关系、优化存储与计算资源,降低人工运维成本。
- 归因分析与价值度量:构建复杂的归因模型,精准量化不同渠道、不同策略对最终成交转化的贡献度,使流量分发的ROI评估更加科学,驱动预算与资源的精准投放。
- 反馈驱动迭代:形成“数据回收 -> 治理与分析 -> 策略优化 -> 效果评估 -> 数据再回收”的完整闭环。数据处理服务不仅被动响应需求,更主动洞察问题、提出优化建议,成为业务增长的“智慧引擎”。
四、未来展望
贝壳找房的数据处理服务将继续向更实时、更智能、更安全的方向演进:探索边缘计算以降低端到端延迟;深化AI在数据治理中的应用;加强数据安全与隐私计算能力,在合规前提下最大化数据价值。
****
贝壳找房的流量分发数据回收与治理之路,是一部从工具建设到体系构建,再到价值创造的演进史。它印证了一个道理:在数据洪流中,唯有通过持续、系统的治理,将原始数据转化为可信、易用、智能的数据服务,才能真正释放数据潜能,赋能业务在激烈的市场竞争中精准航行。这条演进之路,也为行业提供了可资借鉴的数据能力建设范本。
如若转载,请注明出处:http://www.fuchenwork.com/product/72.html
更新时间:2026-06-19 00:59:08